Adding Automatic Deployment Debugging with AI
When I press “Commit & Push” to send brand-new code on its dramatic debut, instead of confetti and fanfare, I’m given a little bop on my head as the scary ❌ icon tells me the deployment failed. There will be no code to show my friends; the link I had copied, intending to share, was overwritten by an error from the deployment logs.
But wait. Why should I be reading logs and debugging a failure when we’ve got AI APIs now?
Well, in this post, I share how I implemented a feature adding an “AI Insights” section for failed deployments while working on dAppling.network, a platform that builds and deploys code to IPFS. These insights should help the user resolve the issue or tell them it’s our fault, and we will fix it. Join me as I prompt-engineer in a React + TypeScript app to make seeing the ❌ a little less painful.
The Ins and the Outs
I decided to use OpenAI’s API because of my familiarity with previous usage, and I somewhat know how the model “behaves” from daily use of ChatGPT. So my first question was, “What inputs should I include to provide the LLM with useful context?” I settled on:
- Deployment logs: where the build actually fails
- User editable settings: commands, variables, GitHub branch
- Commands used to deploy: our build script
- Instructions: the LLM needs a direction
Then, ultimately, the outputs should be usable information to guide the user on how to resolve the problem. I chose:
- What type of failure: our fault or the users
- Reason: why did this fail?
- Solution: how can this be fixed?
- Code and files: suggested changes if necessary
Getting to a String
The model only takes a prompt, but I wanted this to be clean. A big template literal with many variables interspersed seemed not-so-maintainable to me, and that’s when I found LangChain. It helps to put together these variables into a PromptTemplate.
export const getPrompt = ({
model,
logs,
buildStep,
totalBuildTimeSeconds,
buildConfiguration,
forChatGpt = false,
}: {
model: 'gpt-3.5' | 'gpt-4';
logs: string;
buildStep: string;
totalBuildTimeSeconds: number;
buildConfiguration?: string;
forChatGpt?: boolean;
}) => {
const LOG_SIZE = model === 'gpt-4' ? 8_000 : 16_000;
const trimmedLogs = logs.slice(-LOG_SIZE);
const delimiter = '\n"""\n';
return new PromptTemplate({
inputVariables: [
'buildStep',
'buildConfiguration',
'logs',
'instructions',
'buildSpec',
'totalBuildTimeSeconds',
],
partialVariables: {
outputInstructions: forChatGpt ? '' : parser.getFormatInstructions(),
},
template: `{instructions}${delimiter}error log:\n{logs}${delimiter}build step:\n{buildStep}${delimiter}total build seconds:\n{totalBuildTimeSeconds}${delimiter}build configuration:\n{buildConfiguration}${delimiter}build specification:\n{buildSpec}${delimiter}{outputInstructions}`,
}).format({
buildStep,
logs: trimmedLogs,
buildConfiguration,
instructions,
buildSpec,
totalBuildTimeSeconds,
});
};You may be wondering
Aren’t you just using a convoluted template literal?
And to that, I say yes. Because I am injecting the variables at the same time as making the prompt, it looks silly. I thought I should follow the conventions that LangChain has, and I ended up not using any of the advanced prompt features as they did not seem useful for this use case.
Tokens!
In this prompt, there is only one variable that has, well, a variable size. The logs. Basically, the size of the prompt and the output should add up to the context size. For gpt-4, that context is 8k tokens, and for gpt-3.5-turbo-16k, it’s unsurprisingly 16k. Using the Tokenizer app, I calculated LOG_SIZE to be 8,000 characters (not tokens) and 16,000 characters, respectively. Also, you can see I slice with a negative number to get the important part: the end of the logs.
Delimiters
After reading Nader Dabit’s Prompt Engineering Guide, I decided to use """ as a delimiter. I used this to separate the different parts. It is unclear if this is helpful.
Specifying the Format
The prompt includes instructions for the LLM to coax the output using an Output Parser. What I’m using specifically is the StructuredOutputParser with Zod Why I find this totally rad is because Zod is being used in other parts of the codebase, it auto-completes well with GitHub Copilot, and it creates very readable code.
const schema = z.object({
errorCategory: z
.enum([
'systemError',
'configurationError',
'applicationError',
'unknownError',
])
.describe('the error category the error falls into'),
reason: z
.string()
.describe(
'A short description answering the question "why did the build fail?"'
),
solution: z
.string()
.describe(
'A longer description answering the question, "how can this be fixed?" describing possible steps to take to solve the error.'
),
codeSample: z
.string()
.optional()
.describe('an optional code sample if helpful to the user.'),
files: z
.string()
.array()
.optional()
.describe(
'an optional list of files that were affected. if none were affected, this will be empty.'
),
});
export const parser = StructuredOutputParser.fromZodSchema(schema);Output instructions
The resulting parser generates instructions for the LLM with parser.getFormatInstructions(). It first teaches JSON, though that seems unnecessary, and then gives an example. After that, the Zod schema is included and sent along with the prompt. And yes, the whole message, example and all, is included at the bottom of every prompt. The example and even the $schema property. I can’t complain about the extra tokens, though, because the instructions work surprisingly well.
You must format your output as a JSON value that adheres to a given "JSON Schema" instance.
"JSON Schema" is a declarative language that allows you to annotate and validate JSON documents.
For example, the example "JSON Schema" instance
```
{
"properties": {
"foo": {
"description": "a list of test words",
"type": "array",
"items": {
"type": "string"
}
}
},
"required": ["foo"]
}
```
would match an object with one required property, "foo". The "type" property specifies "foo" must be an "array", and the "description" property semantically describes it as "a list of test words". The items within "foo" must be strings.
Thus, the object
```
{
"foo": ["bar", "baz"]
}
```
is a well-formatted instance of this example "JSON Schema". The object
```
{
"properties": {
"foo": ["bar", "baz"]
}
}
```
is not well-formatted.
Your output will be parsed and type-checked according to the provided schema instance, so make sure all fields in your output match the schema exactly and there are no trailing commas!
Here is the JSON Schema instance your output must adhere to. Include the enclosing markdown codeblock:
```json
{
"type": "object",
"properties": {
"errorCategory": {
"type": "string",
"enum": [
"systemError",
"configurationError",
"applicationError",
"unknownError"
],
"description": "the error category the error falls into"
},
"reason": {
"type": "string",
"description": "A short description answering the question 'why did the build fail?'"
},
"solution": {
"type": "string",
"description": "A longer description answering the question, 'how can this be fixed?' describing possible steps to take to solve the error."
},
"codeSample": {
"type": "string",
"description": "an optional code sample if helpful to the user."
},
"files": {
"type": "array",
"items": {
"type": "string"
},
"description": "an optional list of files that were affected. if none were affected, this will be empty."
}
},
"required": ["errorCategory", "reason", "solution"],
"additionalProperties": false,
"$schema": "http://json-schema.org/draft-07/schema#"
}
```Send it off and Hope
The prompt is sent to the OpenAI API, and the response is hopefully good. And hopefully adheres to the schema! Now for the magic part of the parser.
await parser.parse(completion);This line is remarkable. Because the parser has the Zod schema, the response from the AI is automatically parsed into variables that can be used. For example, a recent deployment failure is neatly returned to my code with the following object:
{
"errorCategory": "configurationError",
"reason": "The 'hardhat' package is incompatible with the installed Node.js version.",
"solution": "To fix this error, you can try one of the following solutions:\n\n1. Update the 'hardhat' package to a version that is compatible with Node.js 18.16.0.\n2. Downgrade the Node.js version to a version that is compatible with the 'hardhat' package (e.g., 12.x.x, 14.x.x, or 16.x.x).\n3. Check if there are any other dependencies in your project that have specific Node.js version requirements and make sure they are compatible with the installed Node.js version.",
"codeSample": "",
"files": []
}That means when trying to display it on the frontend, I can update an output variable with the results, pass this object into my InsightsOutput component, and de-structure the expected properties. All well typed.
const [output, setOutput] = useState<Schema>()
// ...
setOutput(response)
// ...
<InsightsOutput insights={output} />
// ...
const InsightsOutput = ({
insights,
}: {
insights?: Schema
}) => {
const { errorCategory, reason, solution, codeSample, files } = insights || {}
return (
// ...
)
}Results
So… Does it provide useful results?
Of course, yes and no. It seems helpful for most of my testing. There have been times when it has been wrong. Impressively, the output parser has always worked. The good thing about the system of prompts and output schema is that trial and error is pretty quick. I think getting it perfect on the first try would be impossible. Anyway, here’s an explanation in the form of a gif.
And a closer look at the output shows that the result actually gives good advice. Well, true advice at least, as we cannot export i18n projects.
use a different deployment method
Telling our users to leave the platform is a funny result. For all I did for the AI, a petty act!
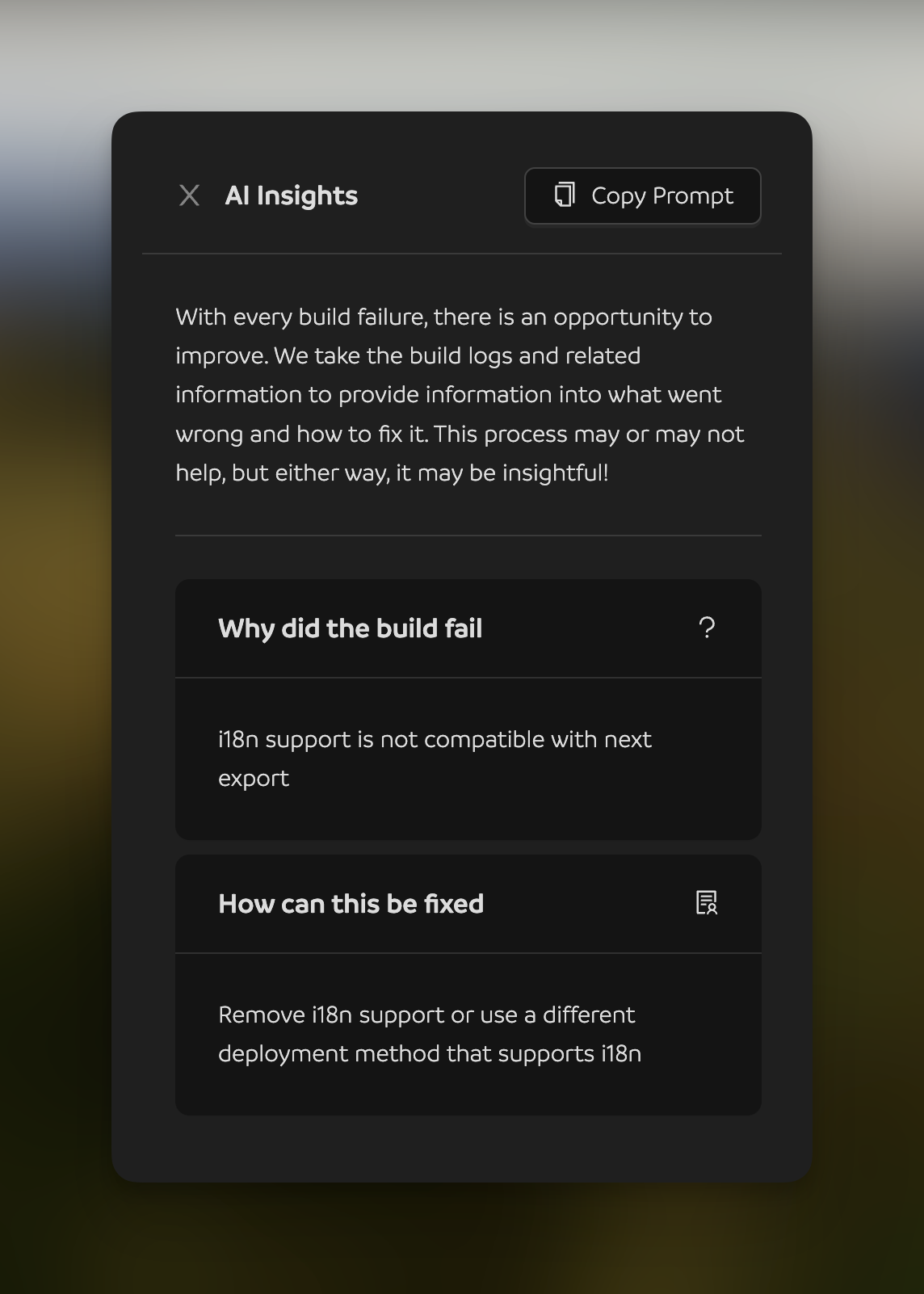
Things I learned
- The temperature should be 0 to ensure the response adheres to the output format.
- The instructions should be at the beginning, and the context should come after.
Go Forth and Fail
Now is the best time to create some failing builds on dAppling.network. We are trying to create the best experience possible for first-time deployments on dAppling and learning from every failure. Using LangChain seems useful, and having Zod schemas makes TypeScript support easy. Providing all the information while balancing the total token amount seemed to produce promising results. If this was interesting to you, I would recommend playing around with prompt engineering. I hope, if you see a ❌ on our platform, you have success working alongside our AI companions.